一次故障的诊断过程–Sysbench 背景 我们的数据库需要做在线升级丝滑的验证,所以构造了一个测试环境,客户端Sysbench 用长连接一直打压力,Server 端的数据库做在线升级,这个在线升级会让 MySQL Server进程重启,毫无疑问连接会断开重连,所以期望升级的时候 Sysbench端 QPS 跌0几秒钟然后快速恢复
但是每次升级都是 Sysbench端 QPS 永久跌0,再也不能恢复,所以需要分析为什么,问题出在哪里?有人说是服务端的问题因为只有服务端做了变更
整个测试过程中 Sysbench 是配置的1-2个连接去压 MySQL Server
Sysbench 介绍 以下介绍来自 ChatGPT-4,用过Sysbench的同学可以跳过这节:
Sysbench 是一个适用于多个系统的多线程基准测试工具,被广泛用于评估不同系统服务的性能,包括数据库系统(如 MySQL、PostgreSQL)、文件I/O、CPU性能以及线程调度。
对于MySQL数据库,Sysbench 可以执行包括但不限于以下类型的测试:
OLTP (Online Transaction Processing) 测试 : 这是最常见的数据库基准测试类型,模拟在线事务处理工作负载,包括事务性的Insert、Update、Delete和Select操作。点查找测试 : 测试数据库针对特定索引的单行查找性能。简单写测试 : 测试数据库进行插入操作的性能。复杂的选择查询测试 : 运行复杂的Select查询,包含多个表和多个条件,测试数据库的读取性能。非事务性查询测试 : 类似于事务查询测试,但不在事务框架内进行。
Sysbench使用Lua脚本语言进行测试案例的开发,它预置了一些标准的测试模板如oltp_read_only、oltp_read_write、oltp_write_only等,这些可以针对数据库执行标准的过程以及自定义的工作负载。
进行Sysbench压力测试的基本步骤包括:
安装Sysbench。
准备测试数据集,这通常涉及Sysbench创建数据库及表,然后填充数据。
执行测试,Sysbench以定义的并发线程数向数据库发送请求。
收集并分析结果,例如吞吐量(每秒事务数)、延迟以及一致性。
一个简单的Sysbench测试命令可以是这样:
1 2 3 4 5 /usr/local/bin/sysbench --debug=on --mysql-user='root' --mysql-password='123' --mysql-db='test' --mysql-host='127.0.0.1' --mysql-port='3307' --tables='16' --table-size='10000' --range-size='5' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --time='11080' --report-interval='1' --histogram='on' --threads=2 oltp_read_write prepare /usr/local/bin/sysbench --debug=on --mysql-user='root' --mysql-password='123' --mysql-db='test' --mysql-host='127.0.0.1' --mysql-port='3307' --tables='16' --table-size='10000' --range-size='5' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --time='11080' --report-interval='1' --histogram='on' --threads=2 oltp_read_write run sysbench oltp_read_write --table-size=100000 --mysql-db=testdb --mysql-user=root --mysql-password=password cleanup
这个命令序列分别准备数据、运行测试和清理环境。运行测试部分变量--threads=4表示使用4个线程,--time=60表示测试持续时间60秒。
使用Sysbench时,请确保执行的测试与你的用例相关,并考虑到可能的性能差异。例如,如果目标是测试Web应用程序的数据库后端,确保测试的查询和事务能够反映真实的使用案例。
Sysbench的使用可以参考这个链接
Sysbench 编译 从 github 下载源代码
以5.10(ALinux3/CentOS8) 为例
1 2 3 4 5 6 7 8 yum install libtool -y //configure.ac:61: error: possibly undefined macro: AC_PROG_LIBTOOL yum install mysql-devel -y 然后: ./autogen.sh ; ./configure ; make ; make install 起压力重现命令: sysbench --mysql-user='root' --mysql-password='123' --mysql-db='test' --mysql-host='127.0.0.1' --mysql-port='3306' --tables='16' --table-size='10000' --range-size='5' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --time='1180' --report-interval='1' --histogram='on' --threads=1 oltp_read_only run --verbosity=5
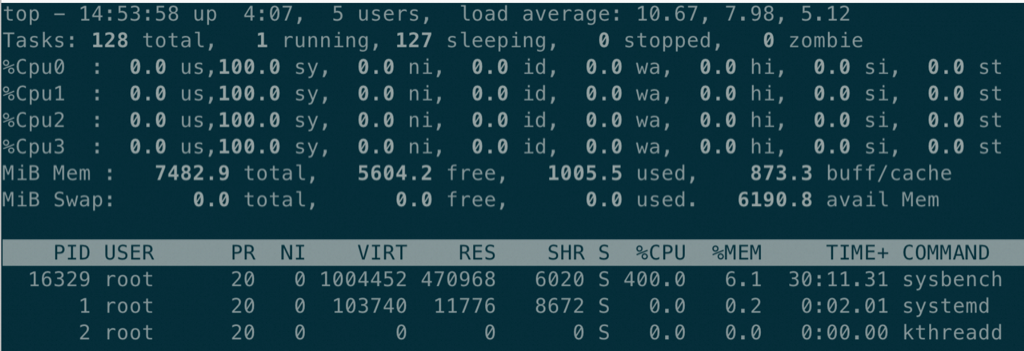
分析 研发人员第一反应重启了Sysbench 所在的ECS 然后恢复了,但是也没有了现场,我告诉他们等有了现场通知我,不要重启。今天终于再次重现了,我连上ECS 速度看了几个指标,通过 top 看到Sysbench 进程占用CPU 400%(整个 ECS 是4核),如图:
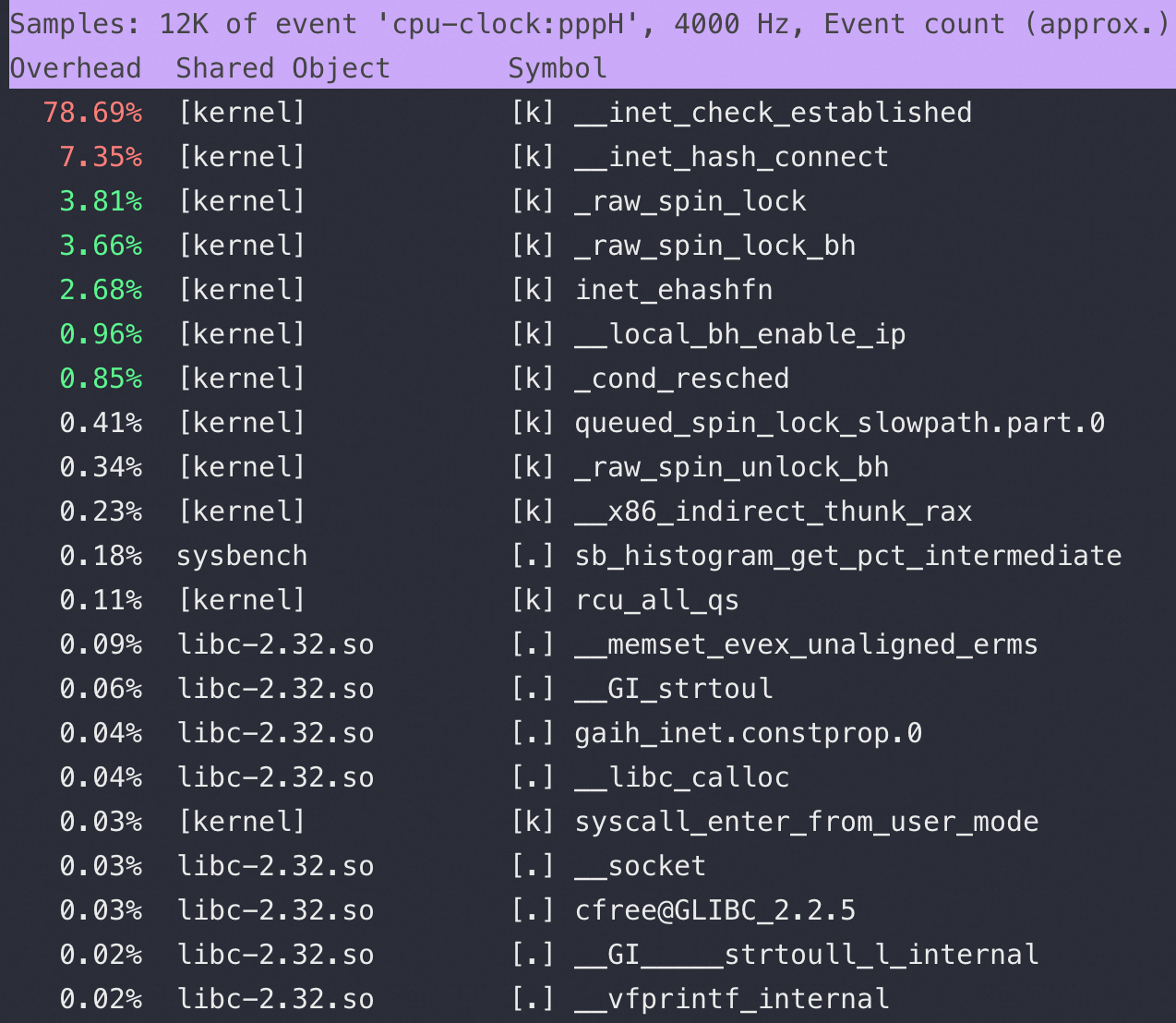
再进一步看看 sys 都在干什么,用 perf top -p 16329 可以看到:
确实是内核态在网络里面有网络方面的函数占比很高,且 spin_lock 严重,所以速度用 ss -s 和 netstat -anto 看看网络连接情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 # ss -s Total: 41682 TCP: 41498 (estab 5241, closed 1, orphaned 0, timewait 0) Transport Total IP IPv6 RAW 0 0 0 UDP 8 5 3 TCP 41497 41495 2 //用了几万个连接了,这不正常 INET 41505 41500 5 FRAG 0 0 0 # netstat -anto | head -30 //确实可以看到几万个连接,几乎都是 CLOSE_WAIT 状态 Active Internet connections (servers and established) 注意第二列一直都是——79,Recv-Q的意思是3306端发给Sysbench的内容79字节,但这79自己还在 OS 的tcp buffer 中,等待Sysbench 读走 Proto Recv-Q Send-Q Local Address Foreign Address State Timer tcp 79 0 192.168.0.1:48743 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:32747 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:40838 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:40190 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:58337 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:23976 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:41687 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:57214 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:30464 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:2015 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:16032 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:47188 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:3054 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0) tcp 79 0 192.168.0.1:46344 192.168.20.220:3306 CLOSE_WAIT off (0.00/0/0)
延伸:Recv-Q 和 netstat 定位性能案例可以看这篇
内核代码 前文通过 perf top 可以看到 __inet_check_established 这个函数占用非常高
不符合正常逻辑,github 内核源码地址 (我只加了注释)
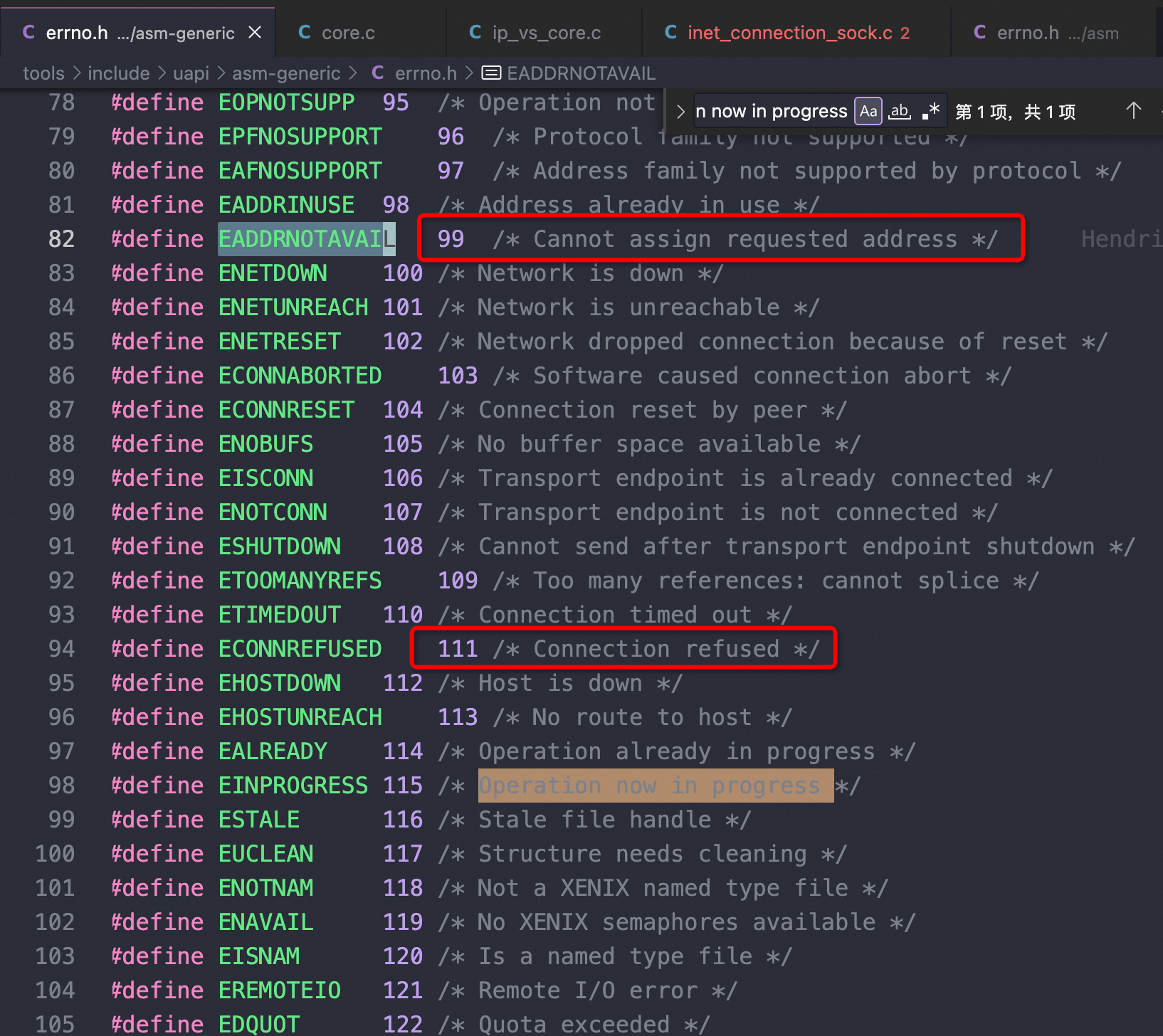
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 //connect()时进行随机端口四元组可用性的判断 //如果本地地址和目标地址组成的元组之前已经存在了,则返回错误码EADDRNOTAVAIL: Cannot assign requested address //这个时候即使设置了REUSEADDR也要报错 /* called with local bh disabled */ static int __inet_check_established(struct inet_timewait_death_row *death_row, struct sock *sk, __u16 lport, struct inet_timewait_sock **twp) { struct inet_hashinfo *hinfo = death_row->hashinfo; struct inet_sock *inet = inet_sk(sk); __be32 daddr = inet->inet_rcv_saddr; __be32 saddr = inet->inet_daddr; int dif = sk->sk_bound_dev_if; struct net *net = sock_net(sk); int sdif = l3mdev_master_ifindex_by_index(net, dif); INET_ADDR_COOKIE(acookie, saddr, daddr); const __portpair ports = INET_COMBINED_PORTS(inet->inet_dport, lport); unsigned int hash = inet_ehashfn(net, daddr, lport, saddr, inet->inet_dport); //inet_ehash_bucket存放ESTABLISHED状态的socket 哈希表 struct inet_ehash_bucket *head = inet_ehash_bucket(hinfo, hash); spinlock_t *lock = inet_ehash_lockp(hinfo, hash); struct sock *sk2; const struct hlist_nulls_node *node; struct inet_timewait_sock *tw = NULL; spin_lock(lock); //遍历检查四元组是否冲突 sk_nulls_for_each(sk2, node, &head->chain) { if (sk2->sk_hash != hash) continue; //INET_MATCH 执行四元组比较 if (likely(INET_MATCH(sk2, net, acookie, saddr, daddr, ports, dif, sdif))) { if (sk2->sk_state == TCP_TIME_WAIT) { tw = inet_twsk(sk2); if (twsk_unique(sk, sk2, twp)) break; } goto not_unique; } } …… not_unique: spin_unlock(lock); return -EADDRNOTAVAIL; //Cannot assign requested address错误,在510行看到了下一节 telnet/strace 中的错误信息 // #define EADDRNOTAVAIL 227 /* Cannot assign requested address */
到这里可以很清楚说明问题在客户端而不是服务端,但是要回答:
为什么CPU这么高,CPU都在忙什么
什么原因会导致 CLOSE_WAIT 状态
为什么Sysbench 要疯狂创建4万多个连接;
所以接下来我们就来分别回答这三个问题
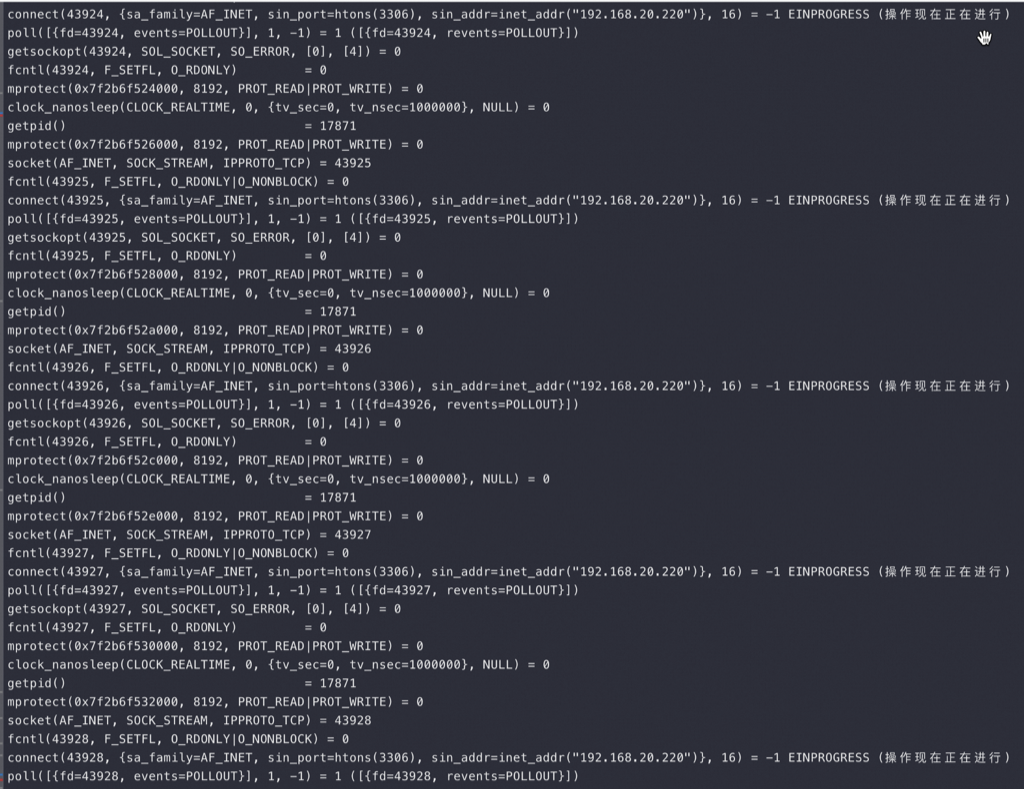
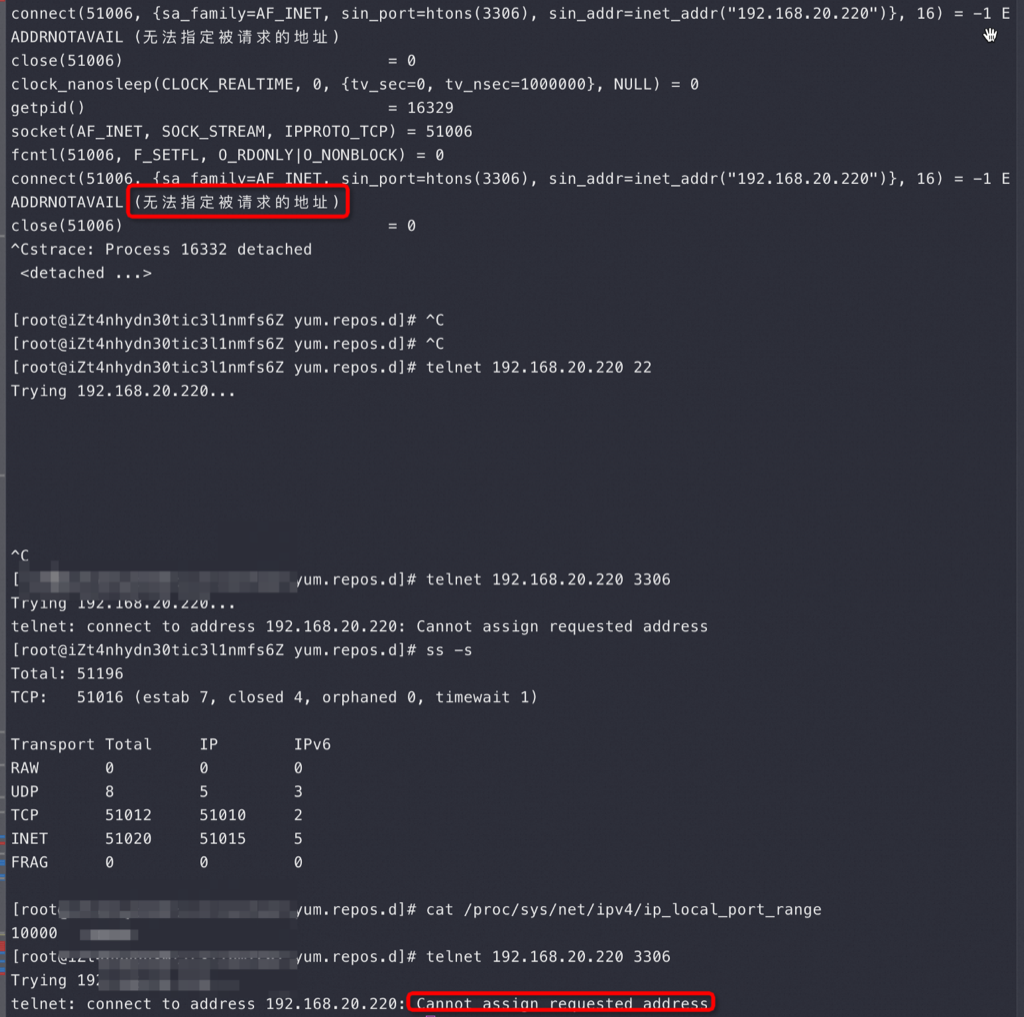
为什么CPU这么高,CPU都在忙什么 首先用 strace -p Sysbench-pid 看看 Sysbench 进程都在忙什么,下图最上面是 Sysbench 在疯狂不断地 connect:
从上图最上面的Strace 来看 Sysbench在疯狂创建连接,但是在Connect 的时候报错:无法指定被请求的地址
那接下来我就要ping 一下 192.168.20.220 这个IP 是OK的,再然后telnet 192.168.20.220 22 发现没报错但是也没有 SSH 让我输密码,于是看了下 cat /proc/sys/net/ipv4/ip_local_port_range 是4万个Local Port 可用,这个时候可以去看看我这篇关于可用端口的经典文章
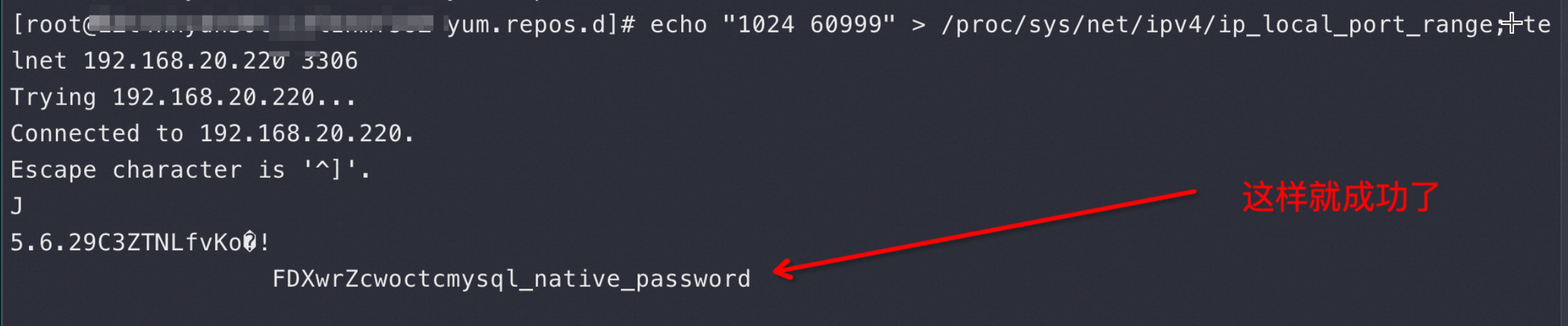
于是我改了下Port Range范围多加了1万Port 上去,然后很快看到如图 ss -s 就有5万连接了,说明你给多少Port 都不够用
同时我也用 telnet 192.168.20.220 3306 报错是:Cannot assign requested address —— 这个报错和 无法指定被请求的地址 很像了,到这里可以看到做一个基本结论:
之所以内核 sys CPU 跑高到 100%,是因为当Local Port 用完,又要新建连接的时候内核会用死循环去找可用端口,导致CPU 跑高(这也是为什么telnet 22端口不会报错,也不会正常出来SSH login——因为抢不到CPU 资源去走选端口的流程)
Cannot assign requested address 和 无法指定被请求的地址 报错是找不到可用端口导致的,还没有走到三次握手,也就是和服务端无关
继续验证:
上图是先把local port 增多,然后立即 telnet 3306 发现成功了!这更是证明了上面的结论2
到这里分析清楚了为什么CPU 高—— Sysbench疯狂建连接导致端口用完,内核要用死循环不断去找可用端口导致了CPU使用率高,因为是内核态的行为所以表现出来就是 sys CPU 100%
而telnet 22端口不报这个错,是因为 22端口的可用端口几万个没有被使用掉,但是22端口也没让我输密码,这里应该是telnet 22时抢不到CPU 造成TCP 三次握手缓慢,但绝对不会报 Cannot assign requested address 错误
什么原因会导致 CLOSE_WAIT 状态 在将这个问题前还是请先去看看 CLOSE_WAIT 代表了什么含义: 为什么这么多CLOSE_WAIT
当同事们看到几万个连接的时候第一反应就是能不能改改这两 Linux 的系统参数:tcp_tw_reuse, tcp_tw_recycle 让端口/连接快速回收?
有没有你们都是这种同事,看到一个现象条件反射得出这个结论,这都是略知皮毛的经验太多了导致 的
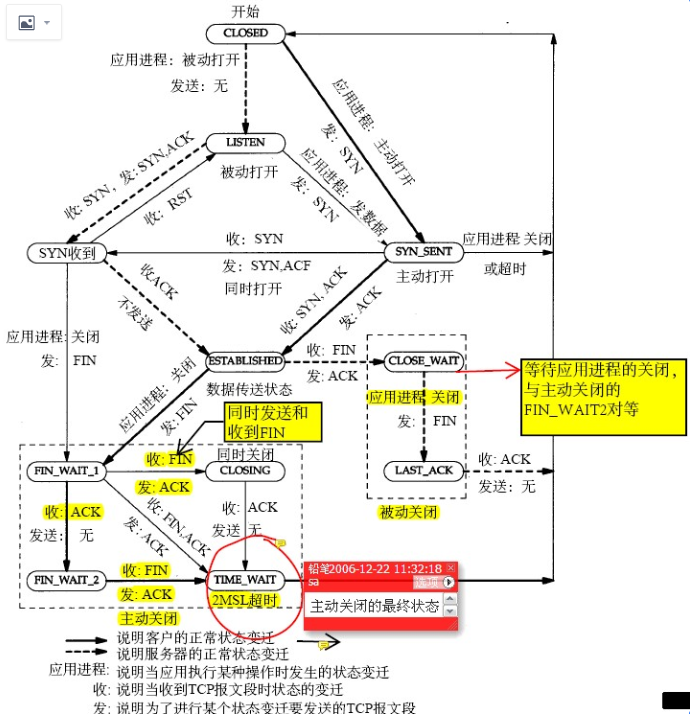
我在 《为什么这么多CLOSE_WAIT》一文中反复提到这张图,以及学霸是怎么从这张图推断原因的:
看完上面这个图和我的 《为什么这么多CLOSE_WAIT》就应该知道 CLOSE_WAIT 就是 Sysbench 没有调 Socket.close 导致的 和内核没有关系,所以改啥内核参数也没有用,因为在这次问题中很多研发同学看到 CLOSE_WAIT 第一反应是去改这些参数:
1 2 net.ipv4.tcp_tw_recycle = 0 net.ipv4.tcp_tw_reuse = 0
如何进一步证明是Sysbench的问题呢?可以抓包看看:
其实上面这个抓包的连接状态是 ESTABLISHED 状态,为什么最终看到的是 CLOSE_WAIT 呢,因为 Server发了 Server Greeting 后有一个超时时间,迟迟等不到Sysbench Client的账号密码就会发 FIN 给Client 端请求断开这个连接,导致Client断的连接状态从 ESTABLISHED 进入 CLOSE_WAIT ,这从上面的 TCP 状态图完全可以推导出来,扩大抓包时间的话会抓到 Server 发过来的 FIN 包
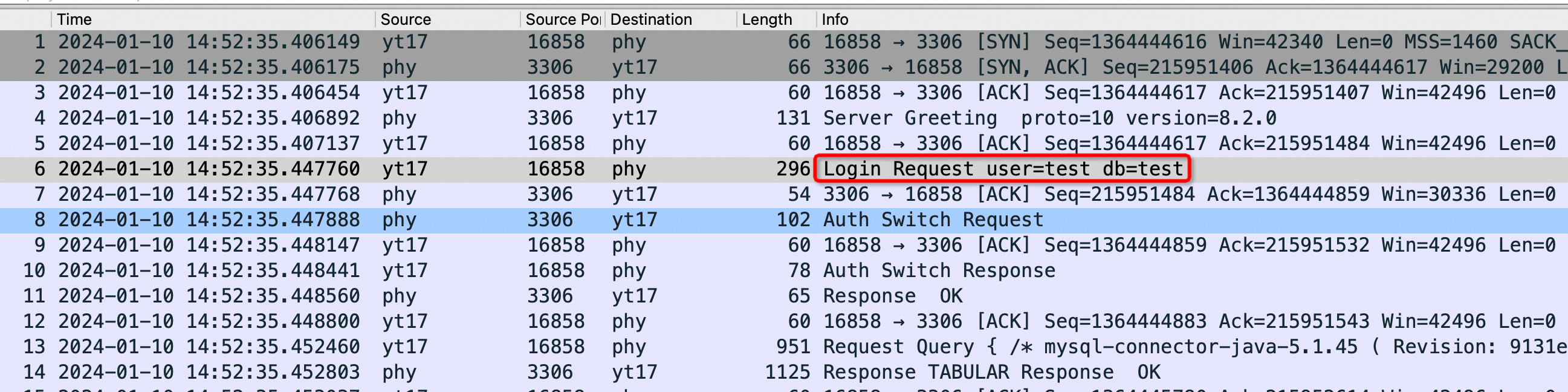
你要看不懂这个抓包,可以找个正常的MySQL-client 连 Server抓一次包,有个正常的对比会很幸福,我丢一个正常的给大家对比参考,上面错在 Sysbench 没有发如下红框的包:
Server 一重启就去看 netstat 的话确实都是 ESTABLISHED:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # netstat -anto | head -30 |grep -E "State|:3306 " Proto Recv-Q Send-Q Local Address Foreign Address State Timer tcp 78 0 192.168.0.1:46344 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:44592 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:45908 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:44166 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:59484 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:60720 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:53436 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:58690 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:35932 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:53944 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:59758 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:53676 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:59304 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:41848 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:44312 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:56654 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:3516 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:39316 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:55074 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:59476 192.168.20.220:3306 ESTABLISHED off (0.00/0/0) tcp 78 0 192.168.0.1:48854 192.168.20.220:3306 ESTABLISHED off (0.00/0/0)
此时端口还够的时候去 strace 看到Sysbench 确实在疯狂 connect 建连接,也不像端口不够的时候会报错:
到这里就可以回答:什么原因会导致 CLOSE_WAIT 状态?因为Sysbench 没有去正常 Login MySQL,MySQL-Server 等了 10 秒也没等到 Sysbenche login 就主动 close 了,而 Sysbench client 一直没有调 Socket.close 来关闭这个连接导致这个连接在 Sysbench 端一直是CLOSE_WAIT 且永久残留为 CLOSE_WAIT
为什么Sysbench 要疯狂创建4万多个连接 为什么Sysbench 要疯狂创建4万多个连接,且还在不停地创建,这就要涉及到 Sysbench 具体代码逻辑(这个版本的 Sysbench 被我厂同事魔改过) ,在一猛子扎进去看代码逻辑前,我换了个开源的 Sysbench 版本(Update 20240325 其实是换了个压测环境,用了不同的Sysbench而已),问题就消失了 —— 有时候猛干不如取巧
到此可以说明问题的原因就是:这个 Sysbench 版本在连接异常断开(Server升级主动断开连接)后,新建连接逻辑错误,疯狂建连接引起的
后来经过网友 扒皮哥和 haoqixu的耐心分析 ,发现这个问题不完是 Sysbench 本身代码的问题,Sysbench 依赖 libmysqlclient.so 包去连MySQL-Server 和处理MySQL 协议等,而这个 Bug 存在 libmysqlclient.so 中,准确来说是MariaDB的 libmysqlclient 中(和版本没关系,最新版还有这个问题),如果换成MySQL Community的 libmysqlclient 就不存在这个问题了。划重点:无论你怎么更换 Sysbench 版本这个问题也无法解决
另外 MySQL 社区和 MariaDB 的 libmysqlclient 只是接口一样,实现完全可以不同,MariaDB 要求连接重连的时候先 close 再init 后才能使用 ,而MySQL 社区版本没有这个要求,所以改 Sysbench 重连的代码也可以 fix 这个问题
这个问题也有人怀疑过OS 的问题,比如换个OS 就好了,但我始终坚持是 Sysbench的问题,因为建连接后不读走TCP buffer里的内容都是业务层面的逻辑(相对于OS Sysbench和libmysqlclient 都是业务层),所以这个错误肯定不在OS
但是很多人换了 OS 就正常了,其实这里不是你只换了 OS,而是换 OS 的时候你顺便把 libmysqlclient 也换了你自己都不知道,这就是我们常说的瞎蒙蒙对了,但是这种经验却是错误的
更换 libmysqlclient 来验证:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 yum remove mariadb-devel -y //删掉 mariadb-devel 所带的 libmysqlclient 18 rpm -i https://dev.mysql.com/get/mysql80-community-release-el8-9.noarch.rpm yum install mysql-community-devel -y //安装 mysql-community-deve ,会带上 libmysqlclient 21 ./configure make install # 查看依赖 objdump -x /usr/local/bin/sysbench |grep libmysqlclient NEEDED libmysqlclient.so.21 required from libmysqlclient.so.21: 0x03532d60 0x00 08 libmysqlclient_21.0 0000000000000000 F *UND* 0000000000000000 mysql_stmt_next_result@@libmysqlclient_21.0 0000000000000000 F *UND* 0000000000000000 mysql_errno@@libmysqlclient_21.0 ... 省略若干 0000000000000000 F *UND* 0000000000000000 mysql_server_end@@libmysqlclient_21.0
自己编译 libmariadb.so 通过下载 mariadb-connector-c-3.3 源码,自己独立编译,新生成的 so 包不再导致CPU飙高,但是TPS 永远跌零,而通过yum 安装的是mariadb-connector-c-3.2.6
此时抓包,可以看到3.3 收到Server Greeting 后也不发送账号密码,但是直接 RST 了连接,这样使得连接被释放,占用端口被释放,CPU不会飙高,但是连接永远无法创建成功,TPS 永远跌零
1 2 3 4 5 6 7 mariadb-connector-c-3.3 抓包: 15100 Mar 27, 2024 17:07:53.422009421 CST 0.001052729 49548 3306 0 49548 → 3306 [SYN] Seq=0 Win=65495 Len=0 MSS=65495 SACK_PERM=1 TSval=1021766452 TSecr=0 WS=128 15101 Mar 27, 2024 17:07:53.422013946 CST 0.000004525 3306 49548 0 3306 → 49548 [SYN, ACK] Seq=0 Ack=1 Win=65483 Len=0 MSS=65495 SACK_PERM=1 TSval=1021766452 TSecr=1021766452 WS=128 15102 Mar 27, 2024 17:07:53.422018506 CST 0.000004560 49548 3306 0 49548 → 3306 [ACK] Seq=1 Ack=1 Win=65536 Len=0 TSval=1021766452 TSecr=1021766452 15103 Mar 27, 2024 17:07:53.422116125 CST 0.000097619 49548 3306 0 49548 → 3306 [FIN, ACK] Seq=1 Ack=1 Win=65536 Len=0 TSval=1021766452 TSecr=1021766452 15104 Mar 27, 2024 17:07:53.422146191 CST 0.000030066 3306 49548 77 Server Greeting proto=10 version=8.2.0 //Server Greeting 15105 Mar 27, 2024 17:07:53.422155229 CST 0.000009038 49548 3306 0 49548 → 3306 [RST] Seq=2 Win=0 Len=0
此时:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #ldd /usr/local/bin/sysbench linux-vdso.so.1 (0x00007ffc3a736000) libmariadb.so.3 => /lib64/libmariadb.so.3 (0x00007f3ce6352000) libdl.so.2 => /lib64/libdl.so.2 (0x00007f3ce634b000) libm.so.6 => /lib64/libm.so.6 (0x00007f3ce6205000) libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007f3ce61ea000) libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f3ce61c8000) libc.so.6 => /lib64/libc.so.6 (0x00007f3ce5fec000) libssl.so.1.1 => /lib64/libssl.so.1.1 (0x00007f3ce5f53000) libcrypto.so.1.1 => /lib64/libcrypto.so.1.1 (0x00007f3ce5c58000) /lib64/ld-linux-x86-64.so.2 (0x00007f3ce63f1000) libz.so.1 => /lib64/libz.so.1 (0x00007f3ce5c3e000) #objdump -x /usr/local/bin/sysbench |grep libmysqlclient 0x0f735338 0x00 04 libmysqlclient_18 #rpm -q --whatprovides /lib64/libmariadb.so.3 mariadb-connector-c-3.2.6-1.al8.x86_64 #yum info mariadb-connector-c-3.2.6-1.al8.x86_64 上次元数据过期检查:0:23:09 前,执行于 2024年03月27日 星期三 16时53分17秒。 已安装的软件包 名称 : mariadb-connector-c 版本 : 3.2.6 发布 : 1.al8 架构 : x86_64 大小 : 545 k 源 : mariadb-connector-c-3.2.6-1.al8.src.rpm 仓库 : @System 来自仓库 : alinux3-updates 概况 : The MariaDB Native Client library (C driver) URL : http://mariadb.org/ 协议 : LGPLv2+ 描述 : The MariaDB Native Client library (C driver) is used to connect : applications developed in C/C++ to MariaDB and MySQL databases.
Sysbench 建连接堆栈,当端口不够的时候很容易抓到 connect 函数,因为connect 需要lookup 可用端口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #pstack 1448113 Thread 3 (Thread 0x7f9a0b23c640 (LWP 1448115)): #0 0x00007f9a0b9722bb in connect () from /lib64/libpthread.so.0 #1 0x00007f9a0bb02b00 in pvio_socket_internal_connect (pvio=0x7f99fa5db270, name=0x7f99fc0247c0, namelen=16) at /root/mariadb-connector-c-3.2.6/plugins/pvio/pvio_socket.c:642 #2 0x00007f9a0bb02d76 in pvio_socket_connect_sync_or_async (pvio=0x7f99fa5db270, name=0x7f99fc0247c0, namelen=16) at /root/mariadb-connector-c-3.2.6/plugins/pvio/pvio_socket.c:750 #3 0x00007f9a0bb03499 in pvio_socket_connect (pvio=0x7f99fa5db270, cinfo=0x7f9a0b23b3d0) at /root/mariadb-connector-c-3.2.6/plugins/pvio/pvio_socket.c:919 #4 0x00007f9a0bb15277 in ma_pvio_connect (pvio=0x7f99fa5db270, cinfo=0x7f9a0b23b3d0) at /root/mariadb-connector-c-3.2.6/libmariadb/ma_pvio.c:484 #5 0x00007f9a0bb0b59c in mthd_my_real_connect (mysql=0x7f99fc01ff50, host=0x14e4110 "127.0.0.1", user=0x14e27c0 "root", passwd=0x14e40c0 "123", db=0x14e28f0 "test", port=3306, unix_socket=0x0, client_flag=65536) at /root/mariadb-connector-c-3.2.6/libmariadb/mariadb_lib.c:1462 #6 0x00007f9a0bb0affb in mysql_real_connect (mysql=0x7f99fc01ff50, host=0x14e4110 "127.0.0.1", user=0x14e27c0 "root", passwd=0x14e40c0 "123", db=0x14e28f0 "test", port=3306, unix_socket=0x0, client_flag=65536) at /root/mariadb-connector-c-3.2.6/libmariadb/mariadb_lib.c:1301 #7 0x000000000041b5d0 in mysql_drv_real_connect (db_mysql_con=0x7f99fc01fbf0) at drv_mysql.c:405 #8 0x000000000041cc6c in mysql_drv_reconnect (sb_con=0x0) at drv_mysql.c:815 #9 check_error (sb_con=sb_con@entry=0x7f99fc0210a0, func=func@entry=0x486637 "mysql_drv_query()", query=query@entry=0x7f99fc0207f0 "SELECT c FROM sbtest16 WHERE id=5031", counter=counter@entry=0x7f99fc0210c8) at drv_mysql.c:894 #10 0x000000000041d1d1 in mysql_drv_query (rs=0x7f99fc0210c8, len=<optimized out>, query=0x7f99fc0207f0 "SELECT c FROM sbtest16 WHERE id=5031", sb_conn=<optimized out>) at drv_mysql.c:1071 #11 mysql_drv_query (rs=0x7f99fc0210c8, len=<optimized out>, query=0x7f99fc0207f0 "SELECT c FROM sbtest16 WHERE id=5031", sb_conn=<optimized out>) at drv_mysql.c:1051 #12 mysql_drv_execute (stmt=<optimized out>, rs=<optimized out>) at drv_mysql.c:1040 #13 0x000000000040f32a in db_execute (stmt=0x7f99fc021270) at db_driver.c:517
修复 改下Sysbench 代码 ./src/drivers/mysql/drv_mysql.c 加一行就可以解决这个问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static int mysql_drv_reconnect (db_conn_t *sb_con) { db_mysql_conn_t *db_mysql_con = (db_mysql_conn_t *) sb_con->ptr; MYSQL *con = db_mysql_con->mysql; log_text(LOG_DEBUG, "Reconnecting zhejian" ); DEBUG("mysql_close(%p)" , con); mysql_close(con); mysql_init(con); while (mysql_drv_real_connect(db_mysql_con)) { if (sb_globals.error) return DB_ERROR_FATAL; usleep(1000 ); } log_text(LOG_DEBUG, "Reconnected" ); return DB_ERROR_IGNORABLE; }
重现 只有sysbench 编译时依赖 libmariadb.so 才会有问题
1 2 3 4 5 #ldd /usr/local/bin/sysbench linux-vdso.so.1 (0x00007ffee0f93000) libmariadb.so.3 => /lib64/libmariadb.so.3 (0x00007fecb3f9d000) yum install mariadb-devel
卸载掉 mysql-devel 重新安装 mariadb-devel, 再编译 sysbench
sysbench 源码下载:https://github.com/akopytov/sysbench
总结 问题结论:mariadb 的 connect lib库对 libmysql 接口实现得有问题,当连接异常断开后会进入死循环疯狂创建连接导致了这个问题
这里涉及很多技巧:top/ss -s/strace/netstat/telnet 以及很多基础知识 local port range/ CLOSE_WAIT ,会折腾很重要,折腾的前提是会解锁各种姿势
难的是如何恰到好处地应用这些技巧和正确应用这些知识,剩下的分析推进就很符合逻辑了
另外我之前强调的在一个错误面前反复折腾不断缩小范围的能力也很重要,比如换个版本确认总比你看代码快吧
从这篇文章可以看出我真是个好教练,一次故障诊断涉及2-3个知识点,3-5个小命令,2-4次逻辑推断,最后完美定位问题,把各个知识的解读、各种命令的灵活使用展现的淋漓尽致。
接下来就是如何在我们的统一实验 ECS 上重现这个问题并保证让大家跟着实际操作
其实开始的时候问题没有这么清晰,每次升级才能稳定重现,后来想要定位问题就必须降低重现难度,考虑到重启客户端ECS 就能恢复,于是:
不再重启ECS,只重启 Sysbench —— 能恢复
不真正升级只重启Server —— 问题能稳定重现,重现容易很多了
不重启 Server,只是kill掉Sysbench 的一条连接 —— 能重现
将Sysbench 连接数从最开始100个,改成2个压 Server,然后 kill 掉 Sysbench 的一条连接 —— 能重现
到最后稳定重现方案就是 Sysbench 用两个连接压 Server,然后到 Server 上随便kill 掉其中一条连接,这个问题能稳定重现;重现后重启Sysbench 就能稳定恢复
参考资料 一个类似的bug 和 https://bugs.mysql.com/bug.php?id=88428
内核笔记 分人分析得再好也是别人的,自己积累的一点点终究是自己的;端口不够的时候CPU 拉高我之前碰到过,所以在内核的代码里写了点笔记,这次Sysbench 问题又碰到了,所以正好看到我上次的笔记:https://github.com/plantegg/linux/blob/3157b476f8216d2655c1c85bad53c975190689ba/net/ipv4/inet_hashtables.c#L447
我的意思是可以拉个Linux 内核较新的代码分支,自己随便哪天学到点啥在上面注释一下,commit,时间久了慢慢就串起来了,如下图错误码和strace 看到的错误信息就是一致的
直播总结:
关于可用端口一文,搞懂这个概念(到底有多少可用端口)只是开始;还需要借助案例去理解;天杀的Google 把端口分为奇偶数两部分,简直是神助攻,给了我们无穷Case 来加深端口不够时候系统什么表现的映像;今天直播的案例是端口全不够了,这种非常明显的异常更好发现;如果端口还够只是偶数用完了,但每次都要扫描一遍偶数,发现偶数没有可用端口再去扫描奇数就能找到可用端口,这导致的是每次可能有点卡顿,但是又不报错,因为过于隐晦这在业务层面带来的危害更加大
同样是学TCP状态流转(ESTABLISHED TIME_WAIT CLOSE_WAIT ),有人看一次就能推理,但大多数都是普通人,看过了还瞎猜,不管啥都想的是 tcp_reuse/tcp_recycle,还处在使劲蒙的状态
ping/telnet/strace/tcpdump 几乎都会用,但是如何恰到好处地去用,报错是什么状态、没任何输出是什么状态
然后就是过程分析中的一些推理。先从最根本的现象QPS 跌0开始撸
三个版本:
不同的 libmysqlclient 版本
现象
yum install mariadb-devel (libmariadb.so 3.2.6)
永远跌零,耗尽端口、CPU高
手工编译 mariadb-connector-c-3.3(libmariadb.so 3.3)
永远跌零,但是不费端口、不耗CPU
yum install MySQL-devel(libmysqlclient 哪个版本都行)
正常
手工编译 libmariadb.so 后 CPU 不飙高,但是TPS 一直跌0,也会疯狂重建连接(每1ms 去建一次连接), 还是没处理对,不过会reset 连接释放端口
如果一个分析推理要求很高的逻辑能力(or 智商),那复制性就不强,没有太大的学习价值(主要是学不会),我们尽量多去学1+1=2这样的逻辑推理,时间久了你就会了1+2=3
真正的高手肯定不只是流于表象:
啊,连不上了
啊,服务器有问题
啊,CPU高
啊,too many Connection
天翼云老哥一年前也发现了这个问题并给了解决办法,但是阅读量只有55 https://www.ctyun.cn/developer/article/405333884604485 ——文章过于简单,如果去学习的话只能看到一个结论
进一步总结 如果3306 端口被防火墙drop,那么: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@plantegg 11:25 /root] #mysql -h127.0.0.1 --ssl-mode=DISABLED -uroot -p123 test mysql: [Warning] Using a password on the command line interface can be insecure. …… 卡着,不报错 strace 看到是这样: futex(0x55b99f129518, FUTEX_WAKE_PRIVATE, 2147483647) = 0 getpid() = 1511313 socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 3 connect(3, {sa_family=AF_INET, sin_port=htons(3306), sin_addr=inet_addr("127.0.0.1")}, 16 一直卡在这里
Too many connections 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 getpid() = 1515762 socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 3 connect(3, {sa_family=AF_INET, sin_port=htons(3306), sin_addr=inet_addr("127.0.0.1")}, 16) = 0 setsockopt(3, SOL_TCP, TCP_NODELAY, [1], 4) = 0 setsockopt(3, SOL_SOCKET, SO_KEEPALIVE, [1], 4) = 0 recvfrom(3, "\27\0\0\0\377\20\4Too many connections", 16384, 0, NULL, NULL) = 27 shutdown(3, SHUT_RDWR) = 0 close(3) = 0 fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0), ...}) = 0 write(2, "ERROR 1040 (HY000): ", 20ERROR 1040 (HY000): ) = 20 write(2, "Too many connections", 20Too many connections) = 20 #mysql -h127.0.0.1 --ssl-mode=DISABLED -uroot -p123 test mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 1040 (HY000): Too many connections 用完端口后: getpid() = 1515928 socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 3 connect(3, {sa_family=AF_INET, sin_port=htons(3306), sin_addr=inet_addr("127.0.0.1")}, 16) = -1 EADDRNOTAVAIL (Cannot assign requested address) shutdown(3, SHUT_RDWR) = -1 ENOTCONN (Transport endpoint is not connected) close(3) = 0 fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0), ...}) = 0 write(2, "ERROR 2003 (HY000): ", 20ERROR 2003 (HY000): ) = 20 write(2, "Can't connect to MySQL server on"..., 54Can't connect to MySQL server on '127.0.0.1:3306' (99)) = 54 write(2, "\n", 1 ) = 1 write(1, "\7", 1) = 1 #mysql -h127.0.0.1 --ssl-mode=DISABLED -uroot -p123 test mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 2003 (HY000): Can't connect to MySQL server on '127.0.0.1:3306' (99)
如果是服务端3306 没起: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 3 connect(3, {sa_family=AF_INET, sin_port=htons(3306), sin_addr=inet_addr("127.0.0.1")}, 16) = -1 ECONNREFUSED (Connection refused) shutdown(3, SHUT_RDWR) = -1 ENOTCONN (Transport endpoint is not connected) close(3) = 0 fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0), ...}) = 0 write(2, "ERROR 2003 (HY000): ", 20ERROR 2003 (HY000): ) = 20 write(2, "Can't connect to MySQL server on"..., 55Can't connect to MySQL server on '127.0.0.1:3306' (111)) = 55 write(2, "\n", 1 ) = 1 write(1, "\7", 1) = 1 rt_sigaction(SIGQUIT, {sa_handler=SIG_IGN, sa_mask=[QUIT], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7f20ab9f0a60}, {sa_handler=SIG_DFL, sa_mask=[], sa_flags=0}, 8) = 0 rt_sigaction(SIGINT, {sa_handler=SIG_IGN, sa_mask=[INT], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7f20ab9f0a60}, {sa_handler=SIG_DFL, sa_mask=[], sa_flags=0}, 8) = 0 rt_sigaction(SIGHUP, {sa_handler=SIG_IGN, sa_mask=[HUP], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7f20ab9f0a60}, {sa_handler=SIG_DFL, sa_mask=[], sa_flags=0}, 8) = 0 exit_group(1) = ? +++ exited with 1 +++ [root@plantegg 11:54 /root] #mysql --show-warnings=FALSE -h127.0.0.1 --ssl-mode=DISABLED -uroot -p123 test mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 2003 (HY000): Can't connect to MySQL server on '127.0.0.1:3306' (111)
账号密码权限错误 1 2 #mysql --show-warnings=FALSE -h127.0.0.1 --ssl-mode=DISABLED -uroot -p1234 test ERROR 1045 (28000): Access denied for user 'root'@'127.0.0.1' (using password: YES)
telnet 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 //正常telnet ,能看到 Greeting以及输密码信息 #telnet 127.0.0.1 3306 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. I 8.2.0�#[6Y @+5=,mi?%#caching_sha2_password^] //当MySQL-Server 的连接数不够了时 #telnet 127.0.0.1 3306 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. Too many connectionsConnection closed by foreign host. //当客户端本地可用端口不够,三次握手还没开始 #telnet 127.0.0.1 3306 Trying 127.0.0.1... telnet: connect to address 127.0.0.1: Cannot assign requested address
99 VS 111 在MySQL错误信息中,ERROR 2003 (HY000)是一个通用的连接失败错误。错误之后的括号中的数字代表的是系统级别的错误码,与MySQL本身的错误代码不同,它们来自于操作系统,表示尝试建立网络连接时遇到了错误。错误码99 和 111 具体代表以下含义:
(99)EADDRNOTAVAIL错误,意义是”Cannot assign requested address”。当尝试绑定到无法分配的本地地址时,就会遇到这个错误。在尝试连接到MySQL服务器时,如果客户端使用了一个不存在的网络接口,例如,错误配置的TCP端口或地址,就有可能产生这个错误。(111)ECONNREFUSED错误,意义是”Connection refused”。当连接请求被远程主机或中间网络设施(如防火墙)明确拒绝时,就会遇到这个错误。在MySQL的上下文中,(111)错误可能表明MySQL服务没有在指定地址或端口上运行,或是防火墙设置阻止了连接。这也可能表明MySQL配置中的bind-address参数错误,设置为了仅允许本地连接。
解决错误99通常需要确保客户端是在向正确配置的地址发起连接,而解决错误111则可能需要检查MySQL服务是否运行、防火墙的设置以及my.cnf或my.ini中bind-address参数的配置。
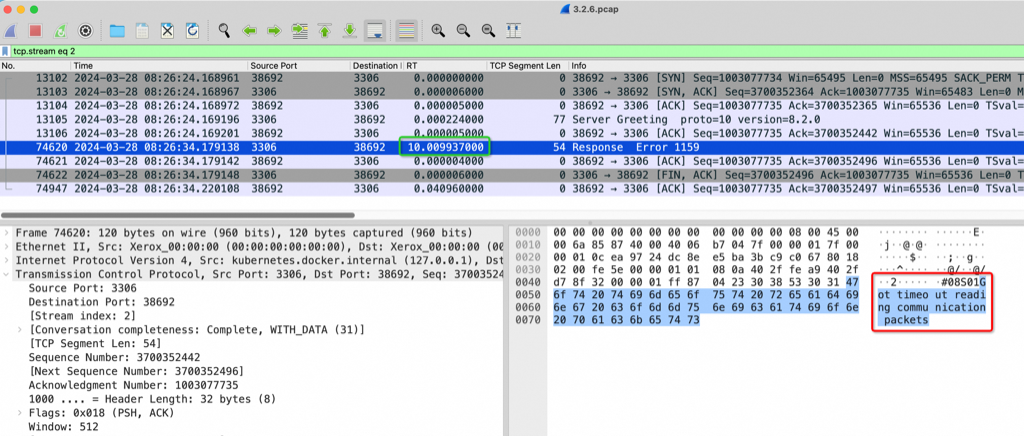
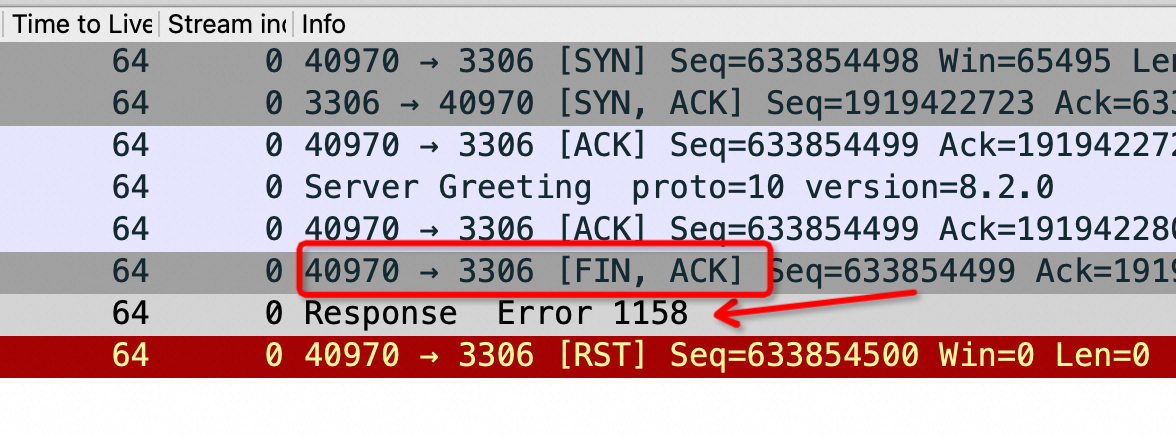
抓包解读 服务端主动断开 如下图是出问题的其中一次抓包,我们可以通过这个抓包来详细解析问题出在哪里。这是Sysbench(38692端口) 主动连MySQL Server(3306 端口),3次TCP 握手正常后Server 发送了 Server Greeting(截图中第四个包),然后Sysbench所在的Linux OS 38692端口回复了ack(这个ack 动作不需要Sysbench参与,完全由OS 来处理),这个时候 Sysbench应该读走这个 Server Greeting包并按MySQL 协议发送客户端账号密码,但是没有,过了10秒钟后(图中绿框) Server 再次发送了 1159 错误也就是图中红框,1159表示 Server等了10秒钟也没等到Client的账号密码,于是超时报错
客户端非正常主动断开 如下图,Server 端回复了 Greeting,本该JDBC Client 发起 login 流程,但是因为这里Server 是 8.0,但是 JDBC Driver 用的5.7 导致兼容性问题,Client 主动断开了
这是 Server 认为通信异常,于是返回:Error message: Got an error reading communication packets 即1158 报错
延伸 类似的分析手段,解决其他问题
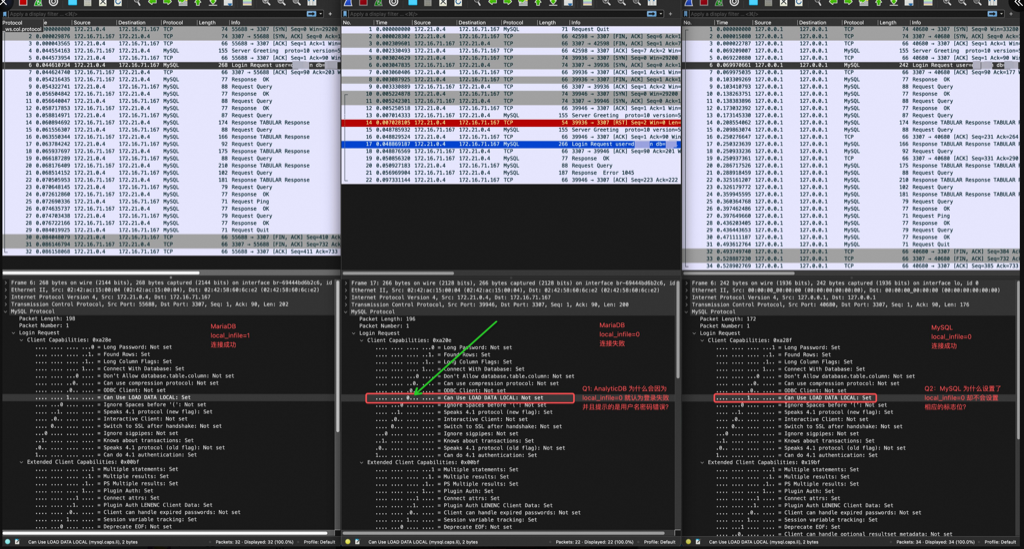
体验抓包分析,的确……很快就找到了问题点。local_infile=0 时,libmariadb 会在 login 包中设置标志位为 0,但是 libmysqlclient 仍然是 1,这是诡异点1。Server DB产品 在标志位为 0 时会报登录信息错误,这是诡异点2。
这条研发人员根据重现的抓包很快定位到了是Server DB产品的Bug,简单来说 Server DB产品对MySQL 协议实现得不好,如图的flag设置为0的话就会被当成 MySQL ping 协议来处理,感叹下还是抓包好使,要不还得去看账号权限啥的
换个MySQL Client 就糊弄过去了;
但是如果去分析就能发现就那一个bit的差异,一定是Server 导致了问题,Server研发在铁的证据面前快速定位是产品bug,但是你如果不会抓包分析,一看报错是账号、权限错误就寄了——程序员对别人说的一个字都不要信,只信自己看到的
再回想想我们平时放弃的那些问题、那些撕逼撕不清楚的锅等等
参考资料 sysbench benchmark MySQL 时候,为什么 kill 连接后,sysbench 没有重连 https://exfly.github.io/why-sysbench-dont-reconnect-after-kill/
LittleFatz:https://www.wolai.com/3cXBGNzWkW7oqKJQ5VKM3X
WindSoilde*:https://articles.zsxq.com/id_9a8b4f87zv6l.html
@邹扒皮.com:https://articles.zsxq.com/id_d27pgzmhuq08.html 最佳作业
最终问题的修复也有星球成员提交给社区并被合并了:https://github.com/akopytov/sysbench/pull/528/files
如果你觉得看完对你很有帮助可以通过如下方式找到我 find me on twitter: @plantegg
知识星球:https://t.zsxq.com/0cSFEUh2J
开了一个星球,在里面讲解一些案例、知识、学习方法,肯定没法让大家称为顶尖程序员(我自己都不是),只是希望用我的方法、知识、经验、案例作为你的垫脚石,帮助你快速、早日成为一个基本合格的程序员。
争取在星球内:
养成基本动手能力
拥有起码的分析推理能力–按我接触的程序员,大多都是没有逻辑的
知识上教会你几个关键的知识点
 上图是在 Sysbench 所在ECS 上抓包可以看到所有连接都是这样,注意第四个包是 Server端在3次握手成功后发了 Server Greeting 给客户端 Sysbench,此时Sysbench 应该发自己的账号密码来 Login但是抓包永远卡在这里,也就是Sysbench 建立完连接后跑了,不搭理服务端发了什么,这也是为什么最前面的 netstat -anto 看到 Recv-Q 这列总是79,这79长度的内容就是 Server 发给Sysbench 的 Server Greeting 内容,本该Sysbench 去读走 Server Greeting 然后按照MySQL 协议发账号密码,但是不,此时Sysbench 颠了,不管这个连接了,又去创建新连接于是重复上面的过程;直到本地端口用完,sys CPU 干到 100%
上图是在 Sysbench 所在ECS 上抓包可以看到所有连接都是这样,注意第四个包是 Server端在3次握手成功后发了 Server Greeting 给客户端 Sysbench,此时Sysbench 应该发自己的账号密码来 Login但是抓包永远卡在这里,也就是Sysbench 建立完连接后跑了,不搭理服务端发了什么,这也是为什么最前面的 netstat -anto 看到 Recv-Q 这列总是79,这79长度的内容就是 Server 发给Sysbench 的 Server Greeting 内容,本该Sysbench 去读走 Server Greeting 然后按照MySQL 协议发账号密码,但是不,此时Sysbench 颠了,不管这个连接了,又去创建新连接于是重复上面的过程;直到本地端口用完,sys CPU 干到 100%